Today I present a novel technique for mapping a point in the 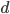 -dimensional plane to its corresponding
-dimensional plane to its corresponding  -bit offset on the
-bit offset on the  th order Hilbert curve with a running time of
th order Hilbert curve with a running time of 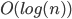 on a processor with -bit words. While a large constant factor makes it infeasible in higher dimensions, it is significantly faster than the previous best method for
on a processor with -bit words. While a large constant factor makes it infeasible in higher dimensions, it is significantly faster than the previous best method for 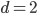 .
.
To explain the approach, let's consider the reverse computation first: mapping an offset on the Hilbert curve to its corresponding coordinates.
Given a -bit number describing the index on the -dimensional Hilbert curve of order , split the index into groups 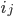 of bits each, starting from the most significant bit. Each of these tuples
of bits each, starting from the most significant bit. Each of these tuples 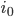 through
through 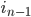 describes both an orthant to recurse into, determining one bit for the each of the coordinates axes (which we'll group together as
describes both an orthant to recurse into, determining one bit for the each of the coordinates axes (which we'll group together as 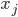 ) of the point on the curve, as well as the transformation that is to be applied to the next recursion level of the curve.
) of the point on the curve, as well as the transformation that is to be applied to the next recursion level of the curve.
We have
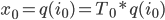
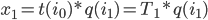
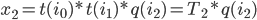

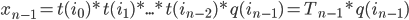
Where 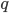 is the function mapping index bits to an orthant,
is the function mapping index bits to an orthant, 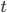 is the function mapping index bits to an element of the transformation group of the Hilbert curve, and
is the function mapping index bits to an element of the transformation group of the Hilbert curve, and  is the operator of that group. If , and are known for a particular dimension, this yields an
is the operator of that group. If , and are known for a particular dimension, this yields an 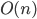 algorithm for mapping offsets on the curve to the corresponding coordinates, and vice versa, by successively computing the product of transformations at each recursion level.
algorithm for mapping offsets on the curve to the corresponding coordinates, and vice versa, by successively computing the product of transformations at each recursion level.
Designing these functions efficiently is rather involved, though, and as far as I'm aware this direct approach has only been applied to the two dimensional case, either via more or less explicit geometric operations (http://www.hackersdelight.org/hdcodetxt/hilbert/lamxy.c.txt), or lookup tables (http://www.hackersdelight.org/hdcodetxt/hilbert/hil_xy_from_s.c.txt, http://www.hackersdelight.org/hdcodetxt/hilbert/hil_s_from_xy.c.txt). For higher dimensions, methods based on Grey codes are usually employed.
In this written form, it is readily apparent that one can apply a prefix scan technique to parallelize the mapping from index to coordinates by computing the partial products of transformations in number of steps logarithmic in the order of the curve. In two dimensions, observe that the group of transformations applied to each quadrant is simply the Klein four-group, which is trivial to implement as a bitwise XOR. This allows us to parallelize across the individual bits of an -bit register, a technique sometimes dubbed SWAR (SIMD within a register). An implementation can be found at http://www.hackersdelight.org/hdcodetxt/hilbert/glsxy.c.txt.
The same method generalizes to higher dimensions; however it quickly becomes infeasible to parallelize within a register as the transformation groups become too complex (in 3D, the transformation group is the alternating group A4, which does not seem to exhibit a structure that would make it particularly efficient to implement).
An open problem until now was to apply the same idea in the other direction: Can mapping a point to the corresponding Hilbert curve index be parallelized in the same way? The issue is that, given 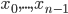 , we can't easily separate the partial product of transformations from the orthant
, we can't easily separate the partial product of transformations from the orthant 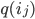 without knowing the transformation of the previous recursion level, making it seem that is impossible to achieve sub-linear time.
without knowing the transformation of the previous recursion level, making it seem that is impossible to achieve sub-linear time.
As it turns out, there is a trick to do exactly that: We can't recover 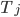 without knowledge of
without knowledge of 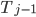 . However, we can compute a function object
. However, we can compute a function object 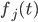 that evaluates under the assumption that
that evaluates under the assumption that 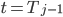 . We now have a semi-group with the operation of functional composition - and can compute the partial sums
. We now have a semi-group with the operation of functional composition - and can compute the partial sums 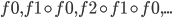 efficiently via a prefix scan. Next, evaluate each function at identity, which yields each of , from which we can recover
efficiently via a prefix scan. Next, evaluate each function at identity, which yields each of , from which we can recover 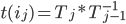 , then
, then 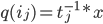 , and finally as is necessarily bijective.
, and finally as is necessarily bijective.
Compared to mapping indices to coordinates, this unfortunately blows up the time complexity by a factor of the order of the transformation group, which appears to be super-exponential in . Combined with the above-mentioned difficulty of efficiently implementing the transformation group, this makes it unlikely that this method has any practical merit except for  .
.
Without further ado, I present my implementation (for 32bit indices), which is three times faster than the lookup table based implemention linked above for 32bits. The code has been extensively transformed and optimized by hand to exploit some further symmetries of the transformation group for , so it bears little resemblance any more to the underlying mathematical structure outlined above.
uint32_t interleave(uint32_t x)
{
x = (x | (x << 8)) & 0x00FF00FF;
x = (x | (x << 4)) & 0x0F0F0F0F;
x = (x | (x << 2)) & 0x33333333;
x = (x | (x << 1)) & 0x55555555;
return x;
}
uint32_t hilbertXYToIndex_logarithmic(uint32_t x, uint32_t y)
{
uint32_t A, B, C, D;
// Initial prefix scan round, prime with x and y
{
uint32_t a = x ^ y;
uint32_t b = 0xFFFF ^ a;
uint32_t c = 0xFFFF ^ (x | y);
uint32_t d = x & (y ^ 0xFFFF);
A = a | (b >> 1);
B = (a >> 1) ^ a;
C = ((c >> 1) ^ (b & (d >> 1))) ^ c;
D = ((a & (c >> 1)) ^ (d >> 1)) ^ d;
}
{
uint32_t a = A;
uint32_t b = B;
uint32_t c = C;
uint32_t d = D;
A = ((a & (a >> 2)) ^ (b & (b >> 2)));
B = ((a & (b >> 2)) ^ (b & ((a ^ b) >> 2)));
C ^= ((a & (c >> 2)) ^ (b & (d >> 2)));
D ^= ((b & (c >> 2)) ^ ((a ^ b) & (d >> 2)));
}
{
uint32_t a = A;
uint32_t b = B;
uint32_t c = C;
uint32_t d = D;
A = ((a & (a >> 4)) ^ (b & (b >> 4)));
B = ((a & (b >> 4)) ^ (b & ((a ^ b) >> 4)));
C ^= ((a & (c >> 4)) ^ (b & (d >> 4)));
D ^= ((b & (c >> 4)) ^ ((a ^ b) & (d >> 4)));
}
// Final round and projection
{
uint32_t a = A;
uint32_t b = B;
uint32_t c = C;
uint32_t d = D;
C ^= ((a & (c >> 8)) ^ (b & (d >> 8)));
D ^= ((b & (c >> 8)) ^ ((a ^ b) & (d >> 8)));
}
// Undo transformation prefix scan
uint32_t a = C ^ (C >> 1);
uint32_t b = D ^ (D >> 1);
// Recover index bits
uint32_t i0 = x ^ y;
uint32_t i1 = b | (0xFFFF ^ (i0 | a));
return (interleave(i1) << 1) | interleave(i0);
}