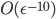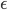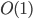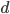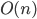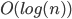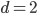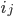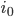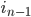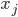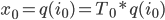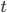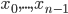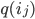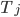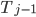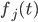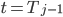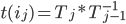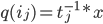In any dimension, the key for an efficient implementation of a coordinate <=> Hilbert curve index mapping is finding a sequence of machine instructions that computes the subcube transformation group of that curve. In particular, if the transformation group multiplication can be represented as a logic circuit, the coordinate <=> Hilbert mapping algorithm can be modified to operate in time logarithmic in the number of bits per coordinate by using bitwise operations and prefix scans at the native register width to massively parallelize the logic circuit.
For this logarithmic algorithm, the Hilbert index => coordinate mapping is straightforward, while the reverse direction to find the Hilbert index given a coordinate tuple requires tracking all possible parent transformation, increasing complexity by a factor of the transformation group's order.
While in every dimension the transformation group is simply some (integer) subgroup of the orthogonal rotation group $O(d)$, clearly this is not a very compact representation, requiring a quadratic number of bits as d increases.
In low dimensions, a compact representation of the transformation group can found through rather tediuos manual geometric or combinatorial work. See previous work http://threadlocalmutex.com/?p=126, http://threadlocalmutex.com/?p=157. While the group in two dimensions (isomorphic to the Klein group V) is trivially representable as a pair of XOR-operations, we find that in three dimensions the group (isomorphic to the alternating group A4) is already quite challenging to represent efficiently as logic circuits. Furthermore, there is no obvious connection between V and A4 that would allow us to extrapolate a possible choice in higher dimensions.
To extend this work to higher dimensions, it's clear the previous manual approach is untenable. Instead, let us try to derive from scratch a recursive definition of higher dimensional Hilbert curves. This will yield an efficient representation of the transformation group in every dimension, from which one can easily derive a log(n) time implementation in 4 dimensions. The general result here matches other treatments of the subject by Butz or Lawder, but we will nevertheless derive it without consideration of prior work in order to solely keep the focus on implementation efficiency.
Before we begin, some comments on the uniqueness of the Hilbert curve in various dimensions are in order. In 2D, the shape of the Hilbert curve is uniquely defined up to similarity (i.e., rotation or reflection). In 3D, there are already 1536 curves unique up to similarity, comprising 6 base curves with 256 subvariants each, each of which flips the spatial orientation for some subset of the 8 octants. Typically the first of those 1536 (in the order listed by Alber and Niedermeier, On Multi-dimensional Hilbert Indexings) is implemented as "the" 3D Hilbert curve. However, we can fix both the base shape of the curve as well as choice of transformation group for each subcube in a way that yields a "canonical" Hilbert curve.
Existing implementations in 2D and 3D typically provide a curve that starts the base curve at (y, x) = (0, 0) resp. (z, y, x) = (0, 0, 0) and ends at (y, x) = (0, 1) resp (z, y, x) = (0, 0, 1). However, for the general construction, it is more convenient to have the base level curve end at the highest coordinate index; i.e., (y, x) = (1, 0) resp. (z, y, x) = (1, 0, 0), which allows recursively composing the base curve to higher dimensions. The difference between the composable and standard variants corresponds to a simple rotation of the coordinate tuples.
To construct the base level curve for dimension d, we start by embedding the base curve of dimension d - 1, which traverses from (0, …, 0) to (0, 1, 0, …, 0), then move into the new dimension (1, 1, 0, …, 0), followed by another copy of the lower dimension curve traversing backwards to (1, 0, 0, …, 0). his constructions matches exactly the construction of a d-bit Gray code via reflections, so we can express the mapping between index tuple and corresponding coordinate tuple as
x(I) = binary2gray(I)
= I ^ (I >> 1)
This Gray code traversal corresponds to the first of the 6 base level curves in Alber and Niedermeier's work, and is the same construction used by Butz and Lawder in higher dimensions.
Now for each of the subcubes along this traversal, we want to apply a transformation that allows mapping the "base edge" of each cube (0, 0, …, 0) -> (1, 0, …, 0), which defines its curve start and end point, to an arbitrary edge defined by transformed start end and points s(I) -> e(I). If we uniquely define how the base edge should be transformed, the transformation of the remainining hypercube vertices follows naturally. In 2D and 3D, we achieved this through rotations about interior diagonals passing through the cube's center. The same concept can be applied in higher dimensions as well.
We can see that a rotation around the cube's "main" interior diagonal (the diagonal from the origin to the far end (0, 0, …, 0) -> (1, 1, …, 1)) that maps cube corners back to cube corners corresponds to a cyclic rotation of the bits representing a cube coordinate, which we'll express x' = x <<< n. For example, for d = 3, a rotation around the axis (0, 0, 0) -> (1, 1, 1) by an angle of 360/d degrees corresponds to a cyclic coordinate shift (x, y, z) -> (y, z, x).
To represent rotations around an other interior diagonals, note that we can first reflect the rotation diagonal to the main diagonal, rotating around the main diagonal, and then performing the same reflection again (its own inverse!) to map back to the chosen diagonal. Expressed in bit log, icif s is one of the two vertices of an interior diagonal, we have
x' = ((x ^ s) <<< n) ^ s = (x <<< n) ^ (s ^ (s >>> n))
Note that the second term (s ^ (s >>> n)) has even parity, and that every bit pattern with even parity can be represented in this form. Thus the group of rotations about interior diagonals is isomorphic to cyclic rotations of the coordinates followed by a even number of reflections of coordinate axes:
x' = (x <<< n) ^ c
where n in [0… d), c in [0..2^d) with parity(c) = 0. It's easy to verify this operation actually forms a group of order d*2^(d-1) which maps fairly well to machine instructions.
Because the parity of c is even, the transformation always includes an even number of reflections, meaning the orientation of each subcube is preserved. In the 3D case, this corresponds to fixing the choice to the first of the 256 subvariants; all 255 others do not preserve orientation. This transform also fulfills our requirement that we find a unique pair (n, c) that transforms the base edge to an arbitrary edge s -> e, which lets us uniquely define a subcube's transformation just from its positioning of the base edge:
(0 <<< n) ^ c = s ((1<<(d-1)) <<< n) ^ c = e
From which follows:
c = s n = ctz(s^e) + 1
Where ctz(x) counts the number of trailing zeroes in the binary representation of x. Although s ^ e is always a non-zero power of two if we chose two vertices directly connected by an edge, we'll define ctz(0) = -1 by convention for later simplification.
This completes that this group construction is indeed suitable for higher dimensional Hilbert subgroups, and in fact, one can verify that this matches the group structure for our manually derived low-dimensional curves. What still remains is finding explicit formulas for s(I) and e(I) for a given Hilbert curve index I; that is, finding an edge traversal that we can use to align the next level of subcubes. The transformation group follows uniquely from this choice.
Since the edge traversal must be connected, the start s(I) of a cube is determined by the end e(I-1) of the previous one:
s(0) = 0 s(I) = e(I - 1) ^ binary2gray(I) ^ binary2gray(I - 1)
Expanding in terms of the the edge vectors s(I) ^ e(I) gives an inductive formula for s(I):
s(I) = e(I - 1) ^ binary2gray(I) ^ binary2gray(I - 1)
= binary2gray(I) ^ (s(I - 1) ^ e(I - 1)) ^ ... ^ (s(0) ^ e(0))
Now the direction of each edge s(I) ^ e(I) can be constructed again by a recursive formulation similar to the main cube ordering. We can find that in 2D, the edge pattern is "x, y, y, x", and in 3D "x, y, y, z, z, y, y, x". Recursively, we can extend the pattern by duplicating it and replacing the middle pair by an edge into the next higher dimension. In 4D, this yields "x, y, y, z, z, y, y, w, w, y, y, z, z, y, y, x". We can find this is expressible as
s(I) ^ e(I) = 1 << ctz(binary2gray(I) & ~(1 << (d - 1)) + 1)
where we're making use of the convention ctz(0) = -1. The combined XOR of these terms yields the pattern "0, 1, 3, 1, 5, 1, 3, 1, 9, 1, 3, 1, 5, 1, 3, 1" for s(I) ^ binary2gray(I) in 4D, which we can concisely generalize as
s(0) = 0
s(I) = binary2gray(I) ^ ((1 << ctz(I)) | 1)
= binary2gray(I) ^ (I & -I | 1)
using the trick that I & -I isolates the least set bit of I.
Putting these all together, this yields an algorithm for transforming from Hilbert curve index to Morton in arbitrary dimensions that maps reasonably well to machine instructions:
uint32_t rol(uint32_t x, uint32_t bits, uint32_t n)
{
assert(bits < n);
return ((x << bits) & ((1U << n) - 1)) | (x >> (n - bits));
}
uint32_t ror(uint32_t x, uint32_t bits, uint32_t n)
{
assert(bits < n);
return ((x << (n - bits)) & ((1U << n) - 1)) | (x >> bits);
}
uint32_t ctz(uint32_t x)
{
// Replace with compiler intrinsic of choice
unsigned long index;
return _BitScanForward(&index, x) ? index : -1;
}
uint32_t hilbertToMortonN(uint32_t index, uint32_t dim, uint32_t bits)
{
uint32_t c = 0;
uint32_t n = 0;
uint32_t mask = (1U << dim) - 1;
uint32_t hibit = 1U << (dim - 1);
uint32_t morton = 0;
for (uint32_t i = 0; i < bits; ++i)
{
uint32_t I = mask & (index >> (dim * (bits - i - 1)));
uint32_t gray = I ^ (I >> 1);
uint32_t M = rol(gray, n, dim) ^ c;
morton = (morton << dim) | M;
uint32_t N = 2 + ctz(gray & ~hibit);
uint32_t C = I == 0 ? 0 : gray ^ (I & -int32_t(I) | 1);
c = rol(C, n, dim) ^ c;
n = (n + N) % dim;
}
return morton;
}
The inverse is found by inverting each operation in the loop:
uint32_t mortonToHilbertN(uint32_t morton, uint32_t dim, uint32_t bits)
{
uint32_t c = 0;
uint32_t n = 0;
uint32_t mask = (1U << dim) - 1;
uint32_t hibit = 1U << (dim - 1);
uint32_t index = 0;
for (uint32_t i = 0; i < bits; ++i)
{
uint32_t M = mask & (morton >> (dim * (bits - i - 1)));
uint32_t gray = ror(c ^ M, n, dim);
uint32_t I = gray2integer(gray);
index = (index << dim) | I;
uint32_t N = 2 + ctz(gray & ~hibit);
uint32_t C = I == 0 ? 0 : gray ^ (I & -int32_t(I) | 1);
c = rol(C, n, dim) ^ c;
n = (n + N) % dim;
}
return index;
}
Up to changing the order of coordinates, this yields the same result as the 2D and 3D algorithms previously published here. Roughly this method is O(n*d), if we allow for dimensions d larger than the native word size, however specializations for specific d should yield significant improvements by eliminating the modulo operation which is comparably slow even on modern architectures unless optimized for some constant.
To implement the log time version of mapping from Hilbert to Morton index hinted at earlier, we now need to supply logic circuits for the main ingredients of the transformation group; that is, cyclic addition of order d and d-bit rotation, as well as some minor bits connective tissue.
Of these, bit rotation is relatively straightforward to represent in circuit logic as a barrel shifter of size O(d*log(d)). This causes complexity to increase from O(d*n) for the linear time implementation to at least O(d*log(d)*log(n)) for the version logarithmic in the bit count; similarly the connective tissue increases complexity, although I have not performed a precise analysis. The main challenge for providing an optimized version for a fixed d however lies in a cyclic addition circuit. When d is a power of two, this is simply a log(d)-bit adder circuit, as we can discard overflow bits. For non-powers-of-two however this circuit is much more complex, which in hindsight somewhat explains the difficulty in constructing an efficient version of it for 3 dimensions. Thus useful candidates for dimensions in which we could expect efficiency gains compared to the linear time version would be (2, 4, 8, 16, …). Clearly one could provide a generic version that works for abitrary d, but constructing the logic circuits on the fly by far outweighs the actual computation performed by the linear time mapping.
Finally, I will present such an implementation for 4 dimensions, where significant work has gone into optimizing the circuits by hand to exploit various symmetries (ss usual, replace pdep and other intrinsics as needed):
uint32_t hilbertToMorton4(uint32_t index, uint32_t bits)
{
// Extract index tuples and align to MSB
uint32_t i0 = _pext_u32(index, 0x11111111) << (32 - bits);
uint32_t i1 = _pext_u32(index, 0x22222222) << (32 - bits);
uint32_t i2 = _pext_u32(index, 0x44444444) << (32 - bits);
uint32_t i3 = _pext_u32(index, 0x88888888) << (32 - bits);
// Gray code
uint32_t gray0 = i0 ^ i1;
uint32_t gray1 = i1 ^ i2;
uint32_t gray2 = i2 ^ i3;
uint32_t gray3 = i3;
// Initial subcube rotations
uint32_t n0 = (gray0 | ~gray1 & gray2) >> 1;
uint32_t n1 = (~gray0 & (gray1 | gray2)) >> 1;
// Prefix sum of subcube rotations
for(uint32_t shift = 1; shift <= 4; shift *= 2)
{
uint32_t s0 = (n0 >> shift) | (~0u << (32 - shift));
uint32_t s1 = (n1 >> shift) | (~0u << (32 - shift));
uint32_t r0 = ~(s0 ^ n0);
uint32_t r1 = (s0 | n0) ^ (s1 ^ n1);
n0 = r0;
n1 = r1;
}
// Map curve indices to flip bits
uint32_t c0 = gray0 ^ (i0 | i1 | i2 | i3);
uint32_t c1 = gray1 ^ (~i0 & i1);
uint32_t c2 = gray2 ^ (~i0 & ~i1 & i2);
uint32_t c3 = gray3 ^ (~i0 & ~i1 & ~i2 & i3);
// Rotate and accumulate flip bits
uint32_t g0 = gray2integer(c0 ^ (n0 & (c0 ^ c3)) ^ (n1 & (c0 ^ c2)));
uint32_t g1 = gray2integer(c1 ^ (n0 & (c1 ^ c0)) ^ (n1 & (c1 ^ c3)));
uint32_t g2 = gray2integer(c2 ^ (n0 & (c2 ^ c1)) ^ (n1 & (c2 ^ c0)));
// Rotate and flip coordinates
uint32_t X = gray0 ^ (n0 & (gray0 ^ gray3)) ^ (n1 & (gray0 ^ gray2 ^ (n0 & i0))) ^ (g0 >> 1);
uint32_t Y = gray1 ^ (n0 & (gray1 ^ gray0)) ^ (n1 & (gray1 ^ gray3 ^ (n0 & i0))) ^ (g1 >> 1);
uint32_t Z = gray2 ^ (n0 & (gray2 ^ gray1)) ^ (n1 & (gray2 ^ gray0 ^ (n0 & i0))) ^ (g2 >> 1);
// Recover W from symmetry conditions
uint32_t W = X ^ Y ^ Z ^ i0;
// Shift back from MSB
X >>= (32 - bits);
Y >>= (32 - bits);
Z >>= (32 - bits);
W >>= (32 - bits);
// Compose to Morton code
return
_pdep_u32(X, 0x11111111) |
_pdep_u32(Y, 0x22222222) |
_pdep_u32(Z, 0x44444444) |
_pdep_u32(W, 0x88888888);
}
In contrast, a logarithmic version of the reverse mapping from Morton to Hilbert curve, as was already implemented for 2D, causes a complexity blow up in the order of the transformation group for simultaneously transforming a set of possible paths for each group element, bringing us to at least O(d*log(d)*2^d*log(n)). Since the two dimensional logarithmic algorithm is already just barely faster in practice than the linear one, which was only achieved through heavy manual optimization, it is unlikely that any higher dimensional instances of this algorithm will be efficient enough, implementation complexity notwithstanding. Thus the 4D version given here will likely be the last O(log(n)) algorithm I will publish.